|
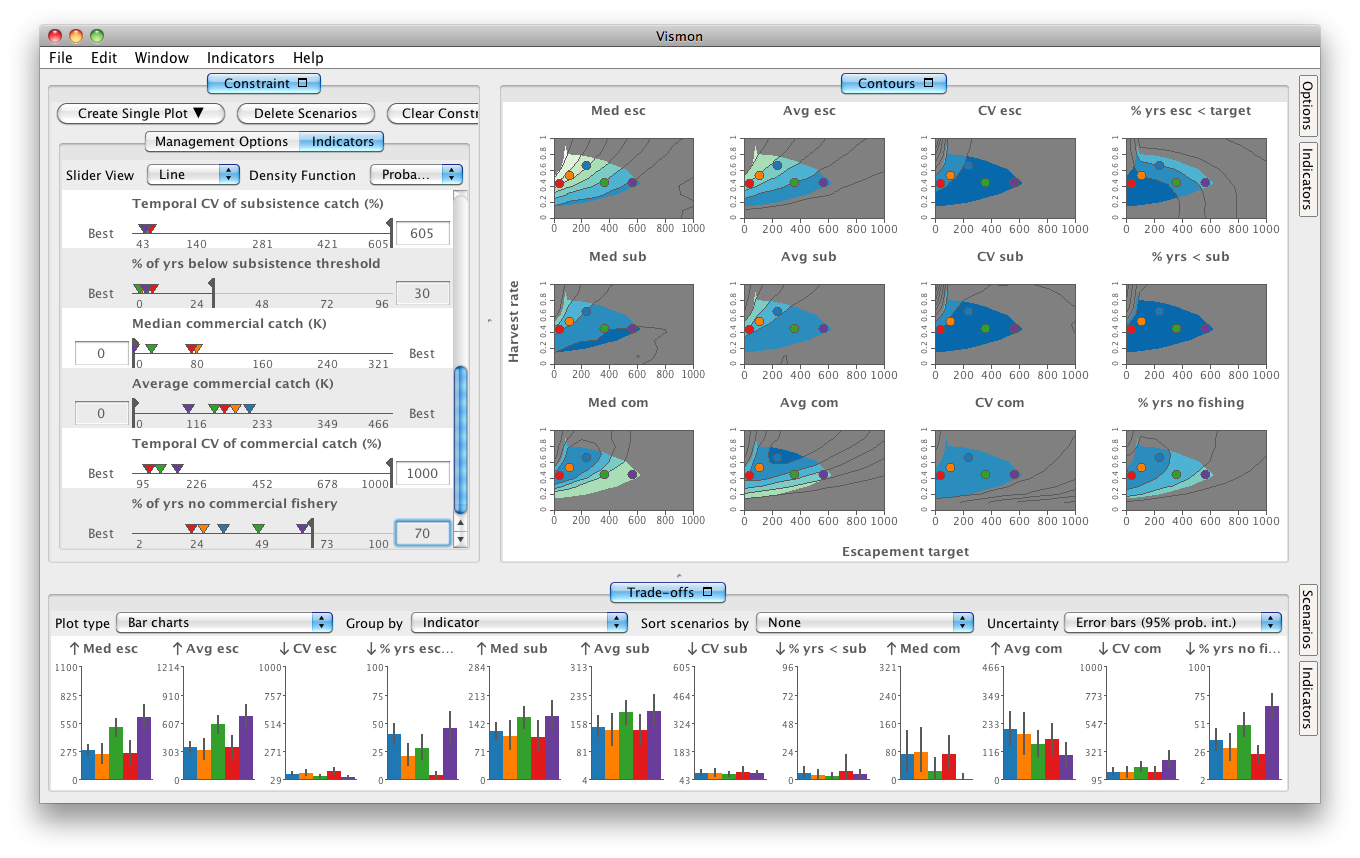
Vismon is a visual tool for fisheries data analysis. The input is a simulation with two input parameters (the management options) and several output indicators. The purpose of Vismon is to help decision makers to quickly narrow down all possible management options to only few that are agreeable to all stakeholders. Then, a detailed trade-off among the few chosen management options can be performed.
Publications
Maryam Booshehrian, Torsten Möller, Randall M. Peterman, and Tamara Munzner. "Vismon: Facilitating Analysis of Trade-Offs, Uncertainty, and Sensitivity In Fisheries Management Decision Making". Computer Graphics Forum (Proceedings of Eurographics Conference on Visualization 2012 (EuroVis 2012)), vol. 31, no. 3, pp. 1235-1244. (pdf)
This paper received the "Second-best paper" award, which is based on the written paper, external reviewers' comments, and the oral presentation at the 2012 EuroVis conference -- Europe's top-ranked conference in data visualization. Only 52 of 207 submissions were accepted for publication and presentation.
|